
On a JSON-copy task with just 30,000 input tokens — 15% of its advertised window — Claude Sonnet 4 fell from near-perfect accuracy to roughly zero in Chroma Research's June 2025 Context Rot study. Not on a reasoning puzzle. On copying JSON. All 18 frontier models Chroma tested degraded as input grew, including models marketed with 1M-token windows.
That result names the gap every agent engineer eventually hits: the distance between advertised context and usable context. Vendors sell 200k, 1M, 10M tokens. Production agents start visibly misbehaving around 50k–100k. The fix isn't waiting for a bigger window — it's restructuring the agent so it never needs one.
TL;DR: Model accuracy, instruction-following, and termination behavior degrade well inside the advertised context window — a phenomenon practitioners call context rot, grounded academically in the "lost in the middle" position bias and the RULER finding that effective context is roughly a third of the advertised number. The engineering response is architectural: treat in-context state as a scarce, lossy resource (the inner loop) and externalize durable state to files, git, and memory stores (the outer loop), with compaction, sub-agents, and prompt caching keeping each turn inside the reliable range.
Key takeaways
- Context rot is monotonic degradation, not an out-of-memory error — it begins long before the window fills, even on tasks unrelated to the extra tokens.
- The "lost in the middle" U-curve is real and replicated: information mid-context can lose 20–40 points of retrieval accuracy versus the same information at the edges.
- Practitioner data (HumanLayer's ~100k coding-agent sessions) puts the "dumb zone" at roughly 50k–100k working tokens for agentic work.
- Newer models are better — but mostly at literal-matching retrieval, not at reasoning or instruction-following over long contexts.
- The durable fix is inner-loop/outer-loop separation: small reconstructed contexts each turn, state externalized to the filesystem and version control.
What context rot actually is
The term surfaced in June 2025, coined by Hacker News user Workaccount2 and amplified the same day by Simon Willison: "performance degrades as context size grows, even on tasks that have nothing to do with the content of the context." That last clause is the important one. This isn't truncation. Nothing falls out of the window. The model simply gets worse at everything as the window fills.
Chroma's controlled study put numbers on it across five experiment types — needle-in-haystack with distractors, JSON copying and corruption detection, counting with irrelevant context, multi-document reasoning. Three mechanisms appear to compound:
- Attention dilution. The relative attention any single token receives falls as the sequence grows, so fine-grained details get lost regardless of where they sit.
- Position bias. The U-shaped curve (next section) means mid-context tokens are systematically under-attended.
- Distractor interference. Plausible-but-irrelevant content measurably drags down accuracy even when it isn't part of the question's evidence.
The benchmarks most teams rely on understate all of this. The NoLiMa benchmark (Modarressi et al., 2025) shows that when retrieval requires reasoning over evidence rather than literally matching a needle string, models collapse: per the paper's reported figures, 17 of 26 tested models scored below 50% even in the 0–32k range, and at 64k+ only 4 of 26 crossed 50%. NVIDIA's RULER benchmark (Hsieh et al., 2024) reaches the same conclusion from a different angle: across multi-hop tracing and aggregation tasks, the effective context of frontier models is roughly one-third of the advertised window. (A caveat for the diligent: a few of these high-precision figures circulate widely in practitioner write-ups but are hard to fully reconcile against the original source text — the direction and rough magnitude are well-supported; treat exact decimals with mild skepticism.)
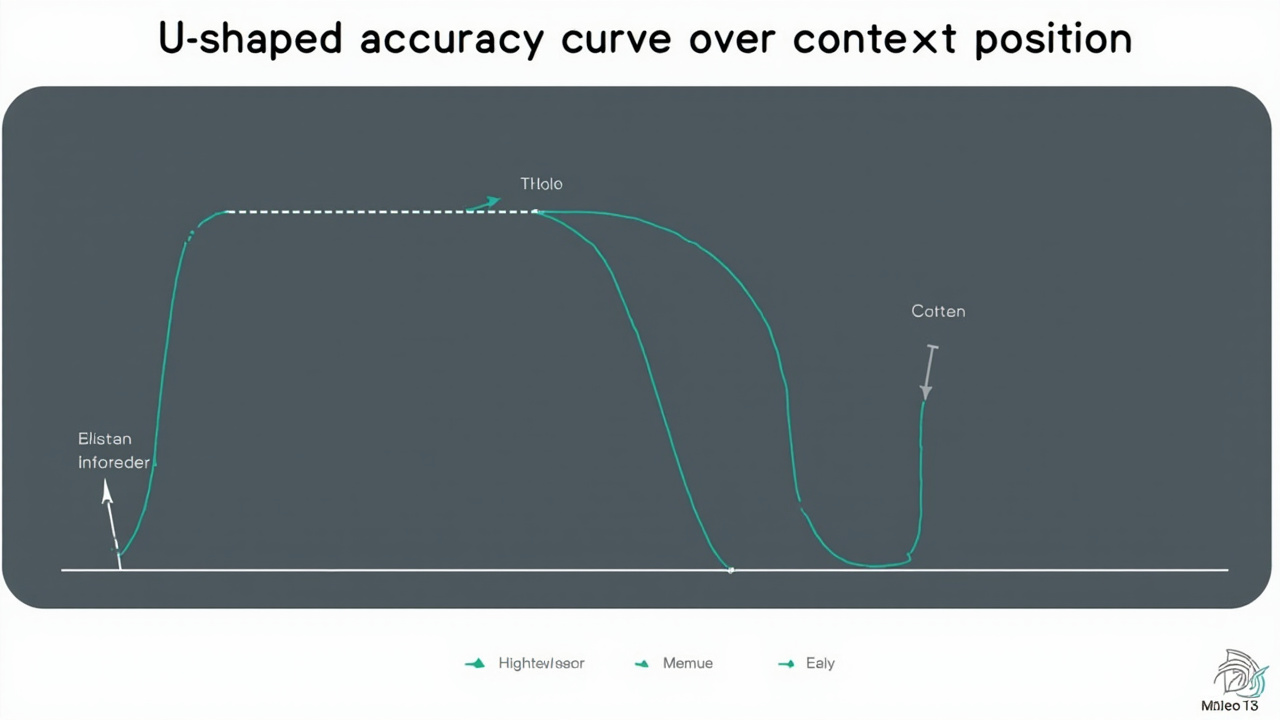
Lost in the middle: the U-curve under it all
The academic anchor is Liu et al.'s "Lost in the Middle" (July 2023, published in TACL 2024). Place a relevant fact at the very start or very end of the context and models retrieve it reliably; place it in the middle and accuracy drops 20–40 percentage points depending on model and task. The mechanism is now well understood: decoder-only transformers over-attend to recent tokens (recency bias) and to initial tokens (primacy, partly attention-sink behavior). The middle gets starved.
Replications through 2024–2025 refined the picture in two ways that matter for agent design. First, the U-shape is worst for lookup-style retrieval and milder for multi-step reasoning. Second, it is reduced but not eliminated in newer models — GPT-4o, Claude 3.5 Sonnet, and Gemini 1.5 all show shallower curves than the GPT-3.5-era models Liu tested, but the curve is still measurable. There's even an argument, from a 2025 paper, that the bias is partly a training artifact rather than purely architectural — which suggests it may keep shrinking, but nobody serious is betting an agent architecture on that.
The agent-design implication is direct: an ever-growing message history slowly migrates your once-recent, still-relevant facts into the attention dead zone. "Infinite" histories fail even when the window technically permits them.
The dumb zone: what practitioners see at ~100k
Dex Horthy's write-up of HumanLayer's analysis of roughly 100k coding-agent sessions coined the term "dumb zone": past ~50k–100k working tokens, Claude Code and similar tools produced dramatically more errors, more tool-call loops, and more premature terminations — well inside the 200k window the model nominally supports.
Drew Breunig's "How Long Contexts Fail" (August 2025) gave the community its canonical failure taxonomy: poisoning (earlier hallucinations treated as fact later), distraction (plausible-irrelevant content derailing output), confusion (losing track of which sub-task is active), and clash (contradictory context — a stale variable name versus a fresh one — causing oscillation). Chroma's study independently documents the same observable symptoms: verbatim repetition of phrases and tool calls, premature termination with empty or truncated responses, hallucinated "quoted" spans that don't exist in the context, and format collapse on structured output.
That last pair is the killer for agents specifically. A chat user shrugs off a truncated answer. An agent loop interprets an empty response as "done" and exits with the task half-finished — or hallucinates a file path and then edits it into existence.
The honest counter-evidence
The dumb-zone narrative is real but incomplete, and credibility requires saying so. Google DeepMind's Gemini 1.5 report demonstrated near-perfect needle-in-haystack retrieval at up to 10M tokens — genuinely impressive, though NoLiMa and RULER both show needle-in-haystack systematically overstates real capability. Anthropic shipped a 1M-token Claude Sonnet 4.5 in production with prompt caching, and RULER leaderboards through 2026 show steady frontier improvement.
The synthesis the field has settled on, articulated across Willison's and Breunig's write-ups: the improvements concentrate in literal-matching retrieval, the upper bound of the window, and cost/latency. They do not concentrate in reasoning over long contexts, instruction-following at long context, or agent-loop reliability — the three things production agents actually need. Context is now cheap to send. Attention is still scarce.
The architectural fix: inner loop, outer loop
The pattern that has won across production agent systems treats in-context state as a scarce, lossy cache and pushes everything durable outside the model. Anthropic's "Building Effective AI Agents" (December 2024) is the most influential articulation: the LLM is the inner loop, repeatedly invoked with a constructed context; the outer loop is durable state — filesystem, version control, structured memory — from which that context is rebuilt each turn. Anthropic's later "Scaling Managed Agents" post (April 2026) sharpens it as decoupling the brain from the hands: the LLM decides in-context, but execution runs in a checkpointed outer loop the agent can resume from even if the context is lost entirely.
Concretely, the outer loop shows up as three artifacts:
A canonical state file. Claude Code's CLAUDE.md, Aider's conventions files, Cursor's project rules — one human-readable file the agent reads at session start and edits incrementally as decisions accumulate.
A progress journal. Both Anthropic's long-running harness guidance and Manus's context-engineering post describe a progress.md recording current goal, what was tried, what worked, what failed, and the next action. Crucially, it is not a transcript — it's a compressed record the agent writes itself, from which the next turn reconstructs a fresh context. Manus credits this pattern with maintaining coherence across 50+ tool-call sessions.
Git as memory. Aider commits after every successful edit; Claude Code uses branches and commit history as the structured record of what changed; the git-worktree pattern gives each parallel sub-agent an isolated working directory so one sub-task's context never bleeds into another's.
Sub-agents are the same principle applied to attention budgets. Anthropic's multi-agent research system reported a 90.2% improvement over a single-agent baseline on a research task — at roughly 15× the token cost. That cost is the price of context isolation, and it's frequently worth paying: each worker's inner loop stays small enough to remain reliable, and the orchestrator absorbs only a summary, never the full transcript.
The mitigation stack
Production agents combine these; none suffices alone. Anthropic is blunt that "compaction isn't sufficient on its own" without state externalization behind it.
| Tactic | What it does | Where it's documented |
|---|---|---|
| Compaction | Summarize/prune history past a threshold before continuing | Anthropic context engineering; Cline Auto Compact |
| Structured note-taking | Write a recap block (goal, last action, result, next step) to a file every turn; rebuild context from it | Anthropic, Manus |
| Sub-agent delegation | Fresh narrow context per sub-task; orchestrator keeps only summaries | Anthropic orchestrator-workers pattern, Claude Code subagents |
| Prompt caching | Stable prefix (system prompt, references, tool defs) cached across turns; only the delta is reprocessed | Anthropic prompt caching |
| Position-aware design | Critical info (current goal, latest error) at the end; stable context at the start; nothing vital in the middle | Liu et al.; Willison |
| Long-term memory stores | Externalize cross-session state with tiered retrieval | mem0, Letta/MemGPT, LangGraph checkpointers |
| Tool-call budgets | Max-iteration cap plus an explicit "am I done?" check before terminating | Anthropic, Manus |
| Hybrid retrieval | RAG injects relevant slices; long context is reserved for working memory of the current task | Hamel Husain's context-rot notes |
Two of these deserve emphasis because they're cheap and routinely skipped. Position-aware design costs nothing: put the current goal and the most recent error at the very end of the prompt, where recency bias works for you. And the termination check is a few lines of harness code that prevents the single worst dumb-zone failure — the agent returning an empty response at 120k tokens and the loop calling it success.
What this means for you
If you're building or operating agents, the operational rules fall out directly:
- Budget working context at roughly a third of the advertised window, per RULER. For a 200k model, treat ~60–70k as the ceiling for reliable agentic work, and trigger compaction well before it.
- Externalize before you compact. A progress file plus git history means compaction loses nothing irrecoverable. Compaction alone is lossy summarization of your only copy of the state.
- Spend tokens on isolation, not accumulation. A 15× token bill for sub-agents that actually finish beats a cheap single agent that loops at 110k tokens.
- Design for the U-curve. Stable prefix first (and cached), criticals last, nothing load-bearing in the middle.
- Instrument for the symptoms. Verbatim-repeated tool calls, shrinking response lengths, and format drift are your early-warning signals that a session has entered the dumb zone — alert on them, don't discover them in the postmortem.
The window-size race will continue, and the models will keep improving at the edges. But the lesson of 2023–2026 is consistent across the academic benchmarks, the vendor engineering blogs, and a hundred thousand logged coding sessions: the advertised context window is a storage spec, not an attention spec. Agents that treat it as storage — and engineer their attention budget separately — are the ones that survive multi-hour sessions. Bigger didn't fix it. Architecture did.
Frequently asked questions
What is context rot?
Context rot is the empirical decline in an LLM's accuracy, instruction-following, and reasoning quality as the active token count grows — even when nothing is truncated and even on tasks unrelated to the added content. The term was coined on Hacker News in June 2025 and rigorously documented by Chroma Research, which found every one of 18 frontier models tested degraded as input tokens grew.
What is the 'dumb zone' in LLM agents?
The dumb zone is the practitioner-observed range — roughly 50k–100k working tokens — where agents start producing more errors, tool-call loops, and premature terminations, well inside the model's advertised window. The term comes from HumanLayer's analysis of ~100k coding-agent sessions, which showed sharp reliability drops past that threshold.
Why don't bigger context windows fix the problem?
Because the failure is attentional, not capacity-based. Research like 'Lost in the Middle' (Liu et al., 2023) and NVIDIA's RULER benchmark shows effective context is roughly a third of the advertised window, with information in the middle of long contexts attended to far less than information at the start or end. A 1M-token window holds the tokens; the model doesn't pay equal attention to them.
What's the most effective mitigation for context rot?
Architectural separation: keep the LLM's in-context working set (the inner loop) small, and externalize durable state — plans, progress, decisions — to files and git (the outer loop), reconstructing a fresh context each turn. Production agents combine this with compaction, sub-agent delegation, prompt caching of stable prefixes, and position-aware prompt design.
Has long-context performance improved in newer models?
Yes, but unevenly. The U-shaped position bias is shallower in GPT-4o, Claude 4, and Gemini 1.5/2 than in the models Liu et al. originally tested, and Gemini 1.5 reported near-perfect needle-in-haystack retrieval at 10M tokens. But the gains concentrate in literal-matching retrieval and cost/latency — not in reasoning, instruction-following, or agent-loop reliability at long context, which are what production agents need.